Lasso回帰
Lasso Regression
Feature Selection task
動機
- Efficiency
- Interpretability(Sparsity)
- which feature is relevant for prediction
手法1: 全部のせ
- 特徴が全くないものから始める
- 次に各特徴でRSSを比較して、その中で一番できの良い物を選ぶ
- 次に2つの特徴を選択して、その中でRSSが一番低いものを選ぶ
- これを続けると、RSSがconvergeしなくなる。そこでやめる(特徴数D)
- そこで、validationやCross validationを使って、各モデルを評価する
- validationとCross validationを分ける
- でもこれは計算量が多すぎる(2D+1)
手法2: Greedy Algorithms(Forward Stepsize)
- 特徴が全くないものから始める
- 全特徴から一つ選択し、一番エラーの低い特徴を咥える(ここまで一緒)
- また全特徴から1つ選択し、一番エラーの低い特徴を加える
- これを繰り返す
- O(D2) -> At most D Steps
- この特徴は、エラーが絶対増えない。また、トレーニングエラーが手法1とおなじになる
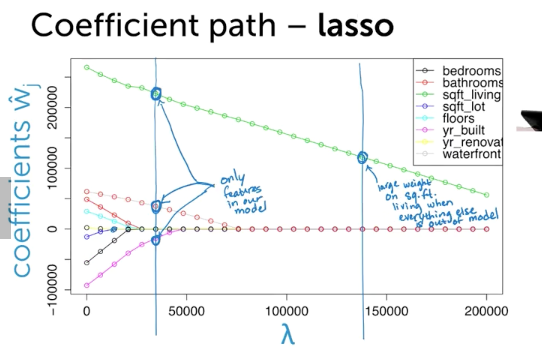
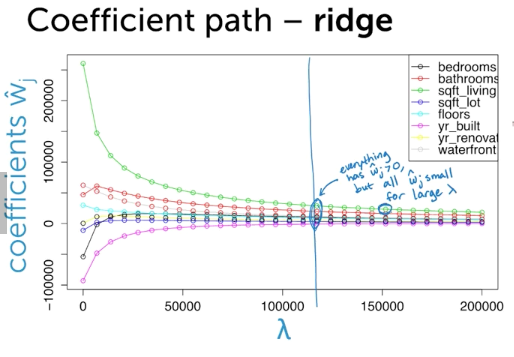
手法3: Regularize(Lasso)
- (復習) Total Cost = measure of fit (RSS) + lambda * measure of magnitude of coefficeints(||w||^2 < - L2 norm)
- 全部の特徴のせモデルから初めて、いらないwを0にする手法
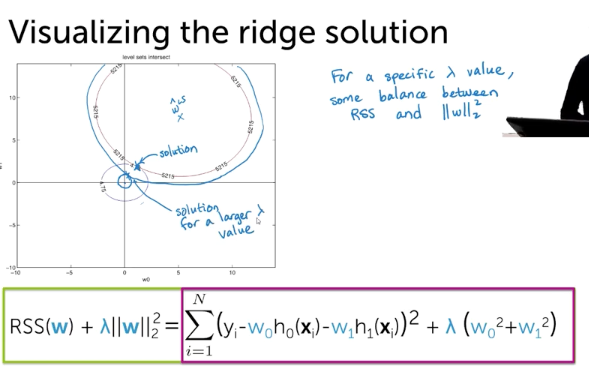
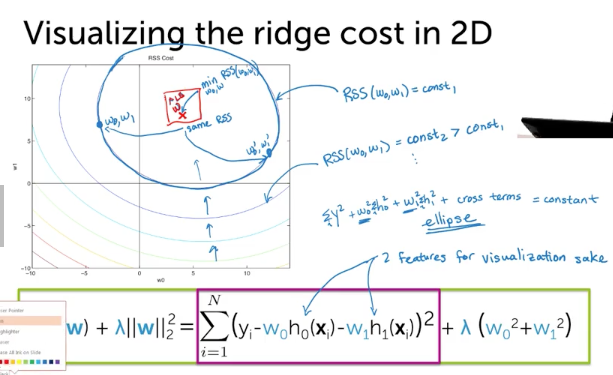
Ridge Cost in 2D
L2Norm
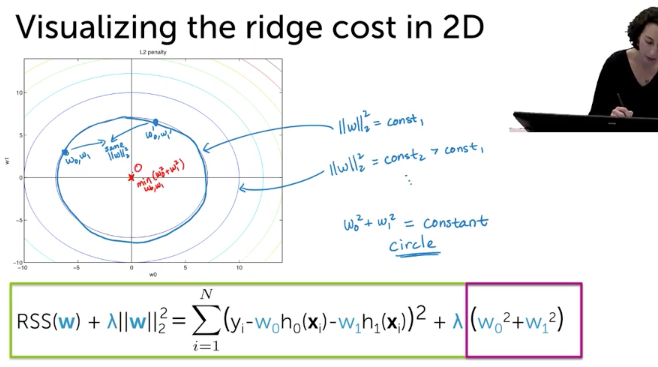
Combined
Lasso Cost in 2D
- RSS will be the same
- L1 Norm
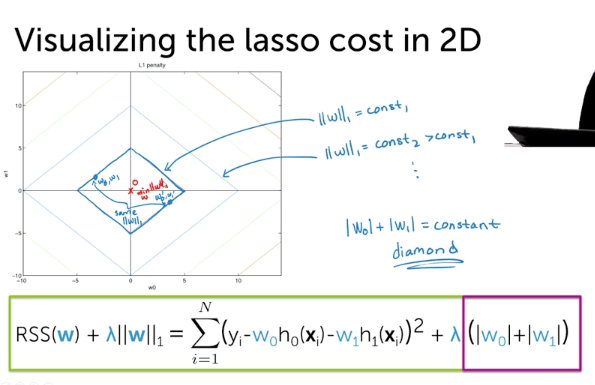
- Combined
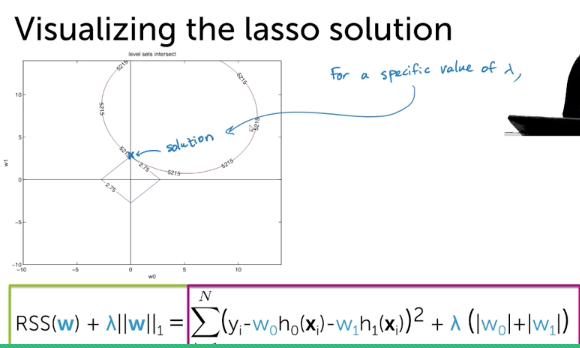
- RSSエラーとL1Normだと、角だとSparse Solutionになる
- hihger dimensionだと、もっとpointierなグラフになるので、角にあたりやすい
optimizing the lasso objective
- issue: derivative of |w|?
- Critical value of derivative? -> does not exist!!
- so do subgradients or coordinate descent
- So no closed-form solution
Coordinate descent (Aside1)
- Converges for lasso object
- Often hard to find min for all coordinates, but easy for each coordkinate ( by fixiing others)
- NO Step Size
- How Do we pick next coordinate ?
- random
Normalizing feature (Aside2)
- take a column data (feature) -> Scale it
- Dont forget to apply same sacle(Zj) to test data
Optimizing least squares objective one coordinate at a time (with normalized features)
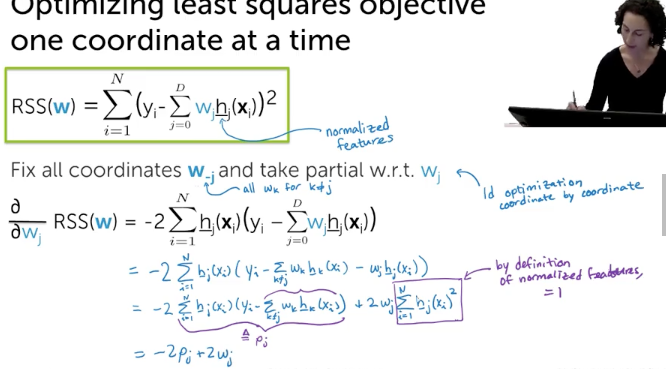
Coordinate Descent


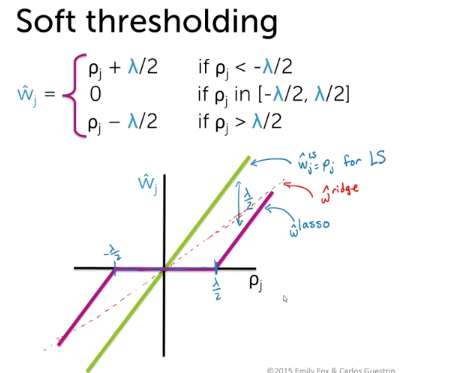
- using soft threasholding
Assessing Convergence
- Max step size

How to choose lambda
same
- big data:divide up into traininset, validation set, test set
- fit w_lambda, select lambda by testing performance of w_lambda, assess generalization error of best w_lambda
- small data: k-fold cross validation
- big data:divide up into traininset, validation set, test set
FOr lasso, you may choose smaller lambda than optimal choice for feature selection
Practical issue
- Lasso shrinks coefficients relative to LS solution
- more bias, less variance
- To lessen bias... run lasso to select feature, then run ls regression with only selected features
- more bias, less variance

Question
- why to sparse
- Why you want to include both correlated feature