GSONでJsonSyntaxException: java.lang.IllegalStateException
下記のようなJSONをマップさせたクラスを作る必要があった。 その中の一つが、別のところで使われているものがあったので、そのまま流用したところ、タイトルのエラーがでた。
public class HogeEntity {
----省略----
@SerializedName("hogehoge")
public HogesEntity hoges;
}
public class HogesEntity {
@SerializedName("hogehoge")
public List<hogehogeEntity> hoges;
}
どうもGSONとしてはオブジェクトを期待していたのに、実際の中身がオブジェクトのリストであるのは良くない模様。HogesEntityをList
ということで、下記にしたら直りました。
public class HogeEntity {
----省略----
@SerializedName("hogehoge")
public List<hogehogeEntity> hoges;
}
CircleCIのAndroidビルドでメモリ不足になった
問題
CircleCIで下記のエラーがでた。
The build VMs have a memory limit of 4G
対応
ヒープメモリの調整
- JVMのヒープサイズ(最大)を指定
machine:
java:
version: oraclejdk8
environment:
gradle_opts: '-dorg.gradle.jvmargs="-xmx512m -xx:+heapdumponoutofmemoryerror"'
Continuous Integration and Deployment
インクリメンタルビルドをオフにする
deployment:
production:
branch: develop
commands:
- ./gradlew assemble -PpreDexEnable=false
Lasso回帰
Lasso Regression
Feature Selection task
動機
- Efficiency
- Interpretability(Sparsity)
- which feature is relevant for prediction
手法1: 全部のせ
- 特徴が全くないものから始める
- 次に各特徴でRSSを比較して、その中で一番できの良い物を選ぶ
- 次に2つの特徴を選択して、その中でRSSが一番低いものを選ぶ
- これを続けると、RSSがconvergeしなくなる。そこでやめる(特徴数D)
- そこで、validationやCross validationを使って、各モデルを評価する
- validationとCross validationを分ける
- でもこれは計算量が多すぎる(2D+1)
手法2: Greedy Algorithms(Forward Stepsize)
- 特徴が全くないものから始める
- 全特徴から一つ選択し、一番エラーの低い特徴を咥える(ここまで一緒)
- また全特徴から1つ選択し、一番エラーの低い特徴を加える
- これを繰り返す
- O(D2) -> At most D Steps
- この特徴は、エラーが絶対増えない。また、トレーニングエラーが手法1とおなじになる
手法3: Regularize(Lasso)
- (復習) Total Cost = measure of fit (RSS) + lambda * measure of magnitude of coefficeints(||w||^2 < - L2 norm)
- 全部の特徴のせモデルから初めて、いらないwを0にする手法
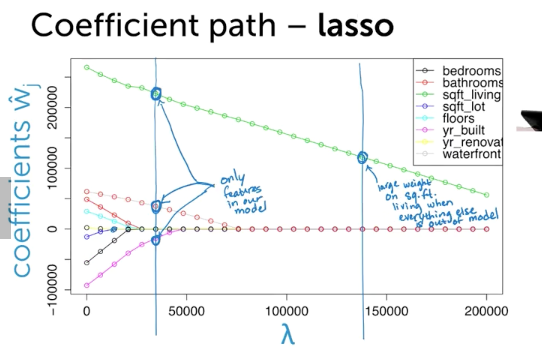
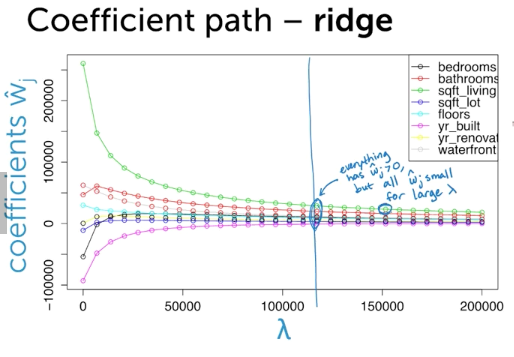
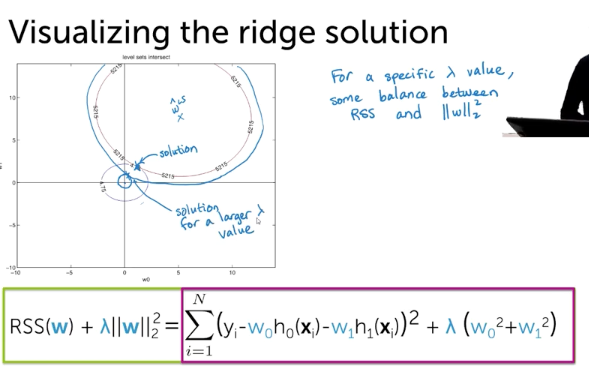
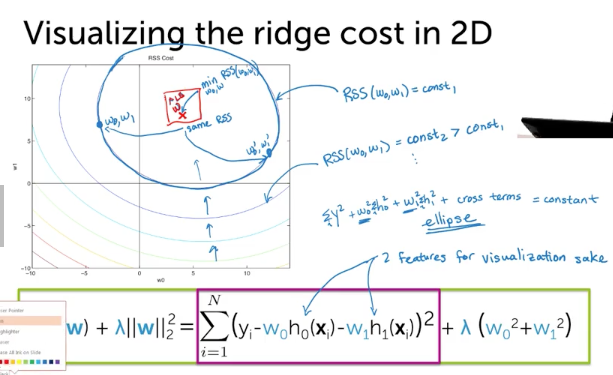
Ridge Cost in 2D
L2Norm
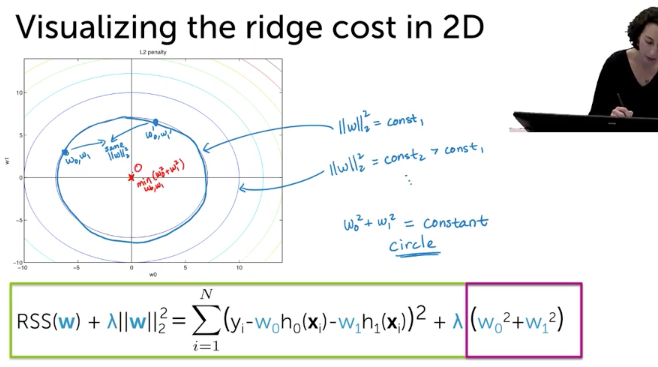
Combined
Lasso Cost in 2D
- RSS will be the same
- L1 Norm
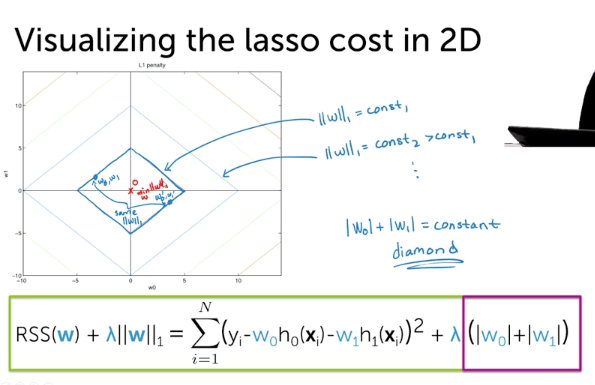
- Combined
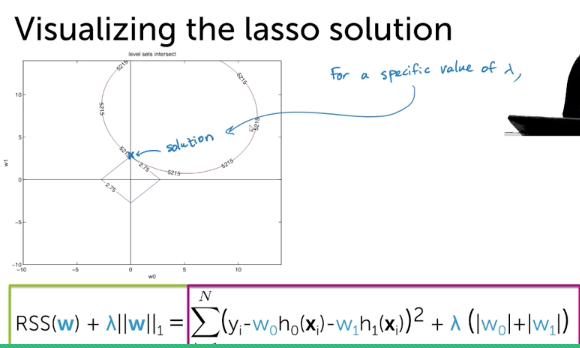
- RSSエラーとL1Normだと、角だとSparse Solutionになる
- hihger dimensionだと、もっとpointierなグラフになるので、角にあたりやすい
optimizing the lasso objective
- issue: derivative of |w|?
- Critical value of derivative? -> does not exist!!
- so do subgradients or coordinate descent
- So no closed-form solution
Coordinate descent (Aside1)
- Converges for lasso object
- Often hard to find min for all coordinates, but easy for each coordkinate ( by fixiing others)
- NO Step Size
- How Do we pick next coordinate ?
- random
Normalizing feature (Aside2)
- take a column data (feature) -> Scale it
- Dont forget to apply same sacle(Zj) to test data
Optimizing least squares objective one coordinate at a time (with normalized features)
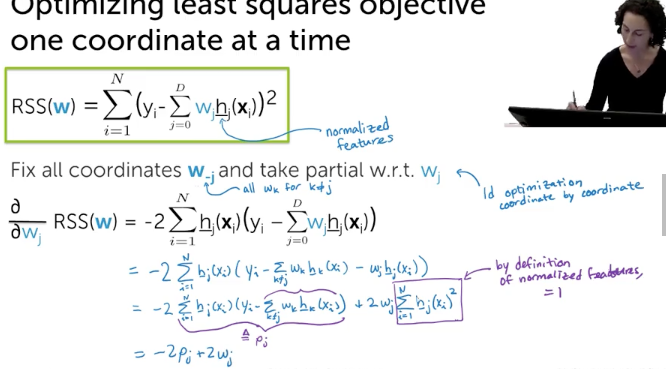
Coordinate Descent


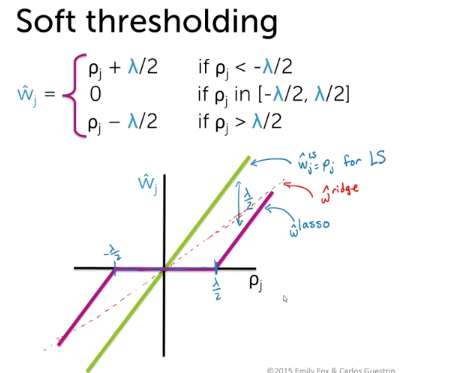
- using soft threasholding
Assessing Convergence
- Max step size

How to choose lambda
same
- big data:divide up into traininset, validation set, test set
- fit w_lambda, select lambda by testing performance of w_lambda, assess generalization error of best w_lambda
- small data: k-fold cross validation
- big data:divide up into traininset, validation set, test set
FOr lasso, you may choose smaller lambda than optimal choice for feature selection
Practical issue
- Lasso shrinks coefficients relative to LS solution
- more bias, less variance
- To lessen bias... run lasso to select feature, then run ls regression with only selected features
- more bias, less variance

Question
- why to sparse
- Why you want to include both correlated feature
2016年の抱負、やること、やらないこと
抱負と目標
- 心技体を充実させる
- あまり抱負と目標を区別せず書いてみた
心
- 一時の感情に流されない。BGの異なる人間とのやり取りでも平常心を保てるようになる(ストレス耐性の向上)
- 一時の感情に流されない。
- 1月中は、週5の瞑想をする
- 気持ちの切り替えをうまくする
- やる気のムラがないようにする
- ポモドーロ・テクニックを取得する
- 継続性を向上する。習慣を持続させる
- インプット・アウトプットを定期的にする
- インプット: feedly記事を毎日読む。1月中は、週3~4の筋トレをする。1月中に8冊本を読む
- アウトプット: まずは、最低週一ブログに何かしら書けるようにする
- 家族と時間を過ごす
- 2月に一度実家へ帰る
- 自ら予定を作り、1月中に自分手動でどこかに行く
技
趣味
- 将棋でアマチュア1級になる
- 1月は棒銀と石田竜でハムをボコる cheap-delicious.hatenablog.com
IT系
- Androidのスペシャリストになる
- Webアプリの作成 in Python
- 1つ作って公開する
- 機械学習の初学者を脱する
- 6月までにCourseraのMachine Learning Specializationを終わらせる
- Regression, Classification, Clustering & Retrieval, Recommender System & Dimensionality Reduction
- 上記のまとめ・わかりにくかった部分を理解する
- Qiita/本ブログにOutputする
- 6月までにCourseraのMachine Learning Specializationを終わらせる
セキュリティ系
- ベンチャーにおけるセキュリティ体制の構築におけるスペシャリストになる
- 上記のIT系とあわせると結構もやっとしてる。自分はどちらに軸足を起きたいのか。今のところ、開発側なんだよな
- セキュリティスペシャリストの評価の仕方など
- 考えをまとめて発信する
お金系
体
- 週3回ジムに行く
- 健康体を保つ
- ベンチ70kg x 3、最大90kgできるようになる
- デッドリフト20kgできるようになる
やらないこと
心
- 本を年間100冊よむこと
- ポーカー(進んでやらない)
- 禅
技
体
- キックボクシングで対人テクを向上させること
- ボルダリング
- スノボ
やるかやらないか迷ってること
技
- IoT
- ブロックチェーンの初心者になる
- まだどうアプローチするか考えてない
- 読んで、実装してみる??
Azure Machine Learningが凄くて震える
この記事は「MoneyForward Advent Calendar 2015」の24日目の記事です。
概要
MicrosoftのAzure Machine Learningに甚く感動したので、そんな思いを書こうと思います。ということをqiitaに投稿しようと思ったら完璧に被ってたので、始めたばかりのハテブに移動 orz
使ってみたきっかけ
Andrew Ng教授のMachine Learningやワシントン州立大学のMachine Learningなどを基礎的なインプットをしてきたので、そろそろ業務にアウトプットしたいな〜と思ってた時に、Azure Machine Learningのセミナー案内が来たのがキッカケです。
Azure Machine Learning Sugeeeee
受講して衝撃を受けました。私が機械学習newbieだからなのかもしれませんが、一瞬、今まで自分が勉強してきたことの意義を疑いかけるほどには、インパクトがありました。以下、Sugeeeと思った点です。
- 簡単 & わかりやすい
- カスタマイズもできそう
- 学習済みモデルをWebAPI化して使える
- Azure Maket Placeで販売もできる
簡単 & わかりやすい
簡単なモデルの生成がGUIベースで作成できます。試しにモデルを評価できるようにしてみましょう。

ご覧の通り、メニューからドラッグ & ドロップでGUIブロックを持ってきて、接続するだけでOkです。又、データをベクトル化して...などもGUIブロックがよしなにやってくれるため、数学初心者も安心して使えます。行列のサイズ間違えなどあまり起きず、安心して使えます。
又、機械学習における各ステップがメニュー内容で上手く分類されているため、全体的なフローをイメージしやすいというのも特徴の一つだと思います。
さらに言うと、各ステップにおける入力値・出力値を確認しやすいので、もし想定外の結果が出力された時のデバッグも楽にできるのではないでしょうか。例として、先ほど追加した評価ブロックの出力をみてみましょう。

この様に出力ノードをクリックし"visualize"を押すだけで、グラフィカルな結果を表示してくれます。単にAccuracyだけでなく、Precision, Recall, Tru Positive数などの数字も表示してくれるので、気配りが効いてますね。
カスタマイズもできそう
簡単なモデルを作るだけなら用意されているブロックを利用すれば事足りると思います。ただ高度なことをしたい時にも対応できる柔軟性もありそうです。メニューをご覧いただければわかりますが、Python/Rのスクリプトを走らせるブロックも準備されているためです。

学習済みモデルをWebAPI化して使える
Azure Machine Learningは学習済みモデルをWebAPI化して使える。後、自分の作ったAzure Machine Learning自体も公開できるようですね。 * ここまでならGoogle Predictions APIもAmazon Machine Learningもできるみたいですが。

販売もできる!
個人的に一番すごいな、と思った部分です。どうやらAzure Market PlaceでAPI化したモデルを販売することも出来る様です。夢が広がりますね。

価格
- Freeプランがあります。制限期間はなさそう。
- Standardプランでは、基本従量課金です。
- 円払い可能ですが、四半期ごとに為替レートで調整される
- MLシートとは???
| 内容 | 料金 |
|---|---|
| ML シート サブスクリプション | ¥1,018.98/シート/月 |
| ML Studio 使用 | ¥102/スタジオ実験時間 |
| ML API 使用 | ¥204/実稼働 API Compute 時間 |
| トランザクション | ¥51/1,000 実稼働 API トランザクション |
まとめ
以上、機械学習がとても楽になるPaaSサービス「Azure Machine Learning」の紹介でした。勿論これらを独自ビジネスに適用して、精度の高いモデルを作るには、機械学習の仕組みを深く理解していないと思います。ただ、機械学習を初めて業務に使ってみたい、とか、スモールに初めてみたい、といった場合にはパワフルで心強いサービスになると思います。
Activ◯ Direct◯ryなどで辛酸を舐めさせられた記憶から、Microsoftに対して余り良い思い出を持っていませんでした。が、Azure Machine Learinigを使ったら、そんな気持ちは吹き飛びました。本当に(m´・ω・`)m ゴメンでした
明日Concurrencyについてm9(^Д^)プギャーられないための基礎知識
本記事はGo その2 Advent Calendar 2015の23日目の記事です。
Go言語どころかナンチャってプログラマーである私が、"Goの強みの一つにConcurrencyがあるんだぜ"とドヤ顔で友人に話した所、十分に理解しておらずm9(^Д^)プギャーられてしまいました。そんな被害者を増やさないために、調査したことを書きます。
目的
Go言語におけるConcurrencyについて概要を理解する。
Concurrencyとは
なんなんでしょう。まずは日本語訳をググってみましょう。
concurrency: 同時並行性
なるほど。最初、私はconcurrency = 並列性だと考えていましたが、いきなり間違えてました。よく考えれば並列だったらparallelismになります。これはm9(^Д^)プギャーられるのも納得です。 次にParallelismもあわせて、その定義を探っていきましょう。
Concurrency vs Parallelism
The Go Blogにおいて下記のような記述がありました。
- concurrency is...
- about dealing with lots of things at once
- parallelism is...
- about doing lots of things at once
なるほど。わからん。もっと読みこんでみました
- Concurrency: Programming as the composition of independently executing processes
- 個々に実行されるプロセスの構成物
- ここでのプロセス≠Linuxプロセス である模様
- Parallelism: Programming as the simultaneous execution of computations
- 処理の同時実行
どうやら、Concurrencyは構成(structure)でありParallelismは実行(execution)である模様。 もっと細かく言うと、Concurrencyは何かしらの問題を解決するために枠組みとして、問題を一つ一つ個々に実行可能なタスクに落とし込める(プログラムの)構成手法のことです。一方、Parallelismはその枠組みを使った問題の解決手法の一つである模様。本当かいな、と思いましたが、少なくともGoでの思想はそうなっているようですね。
Concurrencyの例
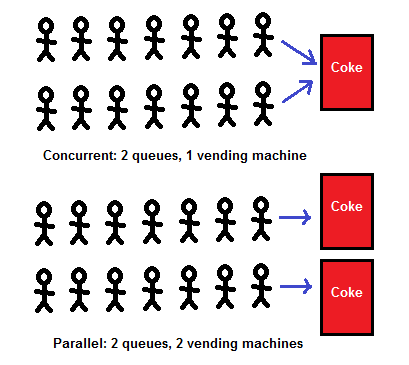
言葉は不要か。図示してみましょう。 * 以下は全て、Concurrency is not Parallelismの画像です
Gopherちゃん初めての焚書
 一匹のGopherちゃんが積ん読された大量のマニュアルを焼却炉に破棄しようとしています。これにおける問題は「積読マニュアルを焼却する」といったことにあります。またこの問題を「実行」するのがGopherちゃんです。これをConcurrencyな構成(Concurrency Composition)にしてみましょう
一匹のGopherちゃんが積ん読された大量のマニュアルを焼却炉に破棄しようとしています。これにおける問題は「積読マニュアルを焼却する」といったことにあります。またこの問題を「実行」するのがGopherちゃんです。これをConcurrencyな構成(Concurrency Composition)にしてみましょう
Concurrencyな構成パターンA
この問題において「一部の積読マニュアルを拾って、運搬し、焼却炉で燃やす」といった単位でタスクを捉えるならば、もう一匹別のGopherちゃんと焼却炉を準備すれば、問題解決に向けた構成(concurrent composition)が設計できます。

このパターンでは、同じタスクを実行させる、というParallelismになっています。ただし、上記の構成ですと片方のGopherちゃんがサボったり、積読本の中のジャンプを読み始めたりする可能性もあります。つまり2匹のGopherちゃんが「同時実行しない」可能性があるということなので、何かしらの問題でParallelismではなくなることもあります(Conccurentではあり続ける)
Concurrencyな構成パターンB
下記の図がConcurrencyな構成その2です。タスクを「積読マニュアルをカートに入れる」「運ぶ」「燃やす」といった単位で切り出し、それぞれのタスクをGopherちゃんが実行しています。ここでは、何かしらのトラブルがなければ、Gopherちゃん達は各々のタスクを同時実行しているのでParallelismが実現しているといえます。

Concurrencyな構成パターンC
下記の図はパターンBの発展形です。「運ぶ」タスクを細分化しており、「本が入ったカートを運ぶ」タスクと「空になったか−とを運ぶ」タスク及び実行担当のGopherちゃんが追加されています。

Concurrencyな構成パターンD
今度はタスクを「積読本を中継地点まで運ぶ」タスクと「中継地点から焼却炉まで運んで燃やす」タスクにわけてみましょう。切り分け単位が焼却するまでの動作ではなく、積読マニュアルをどこまで運ぶかの距離となっています。

Concurrencyな構成パターンE
これはパターンAとパターンDの合わせ技です。片方の焼却炉が死んでも、もう片方の焚書ミッションは継続できるので、そちらでのParallelismは維持されます。

Concurrencyな構成パターンF
パターンA~パターンEをがっちゃんこしたやつ。Gopherちゃんが沢山いて、可愛くてつらい。

現実に置き換えると
まとめ
以上のことから、Concurrencyとは何かしらの問題に対するアプローチの仕方であり、設計であるとの模様です。そしてその設計の仕方により、Parallelismを実装するかどうか、そしてどう実装するかが、変化する、ということを理解しました。少なくともGo言語においては、その整理でよいのではないでしょうか。
おまけ: 色々なConcurrency vs Paralellism